
Xinyu Yang
CS Ph.D. student at Cornell University
About Me
Hi! I am Xinyu Yang (杨心妤), a CS Ph.D. student at Cornell University advised by Prof. Jennifer J. Sun. My research interest lies in Machine Learning and Computer Vision.
Previously, I got my bachelor's degree (2019-2023) in Computer Science and Technology from Zhejiang University. During my undergraduate, I was fortunate to work with Prof. James Zou at Stanford and Prof. Fei Wu at ZJU.
News
- Feb 2026 One first-author paper accepted to CVPR 2026.
- Feb 2026 Joining Google Deepmind as a student researcher in Los Angeles.
- Dec 2025 One co-first-author paper published in Science.
- Sep 2025 One paper accepted to NeurIPS 2025.
Publications
* denotes equal contribution
-
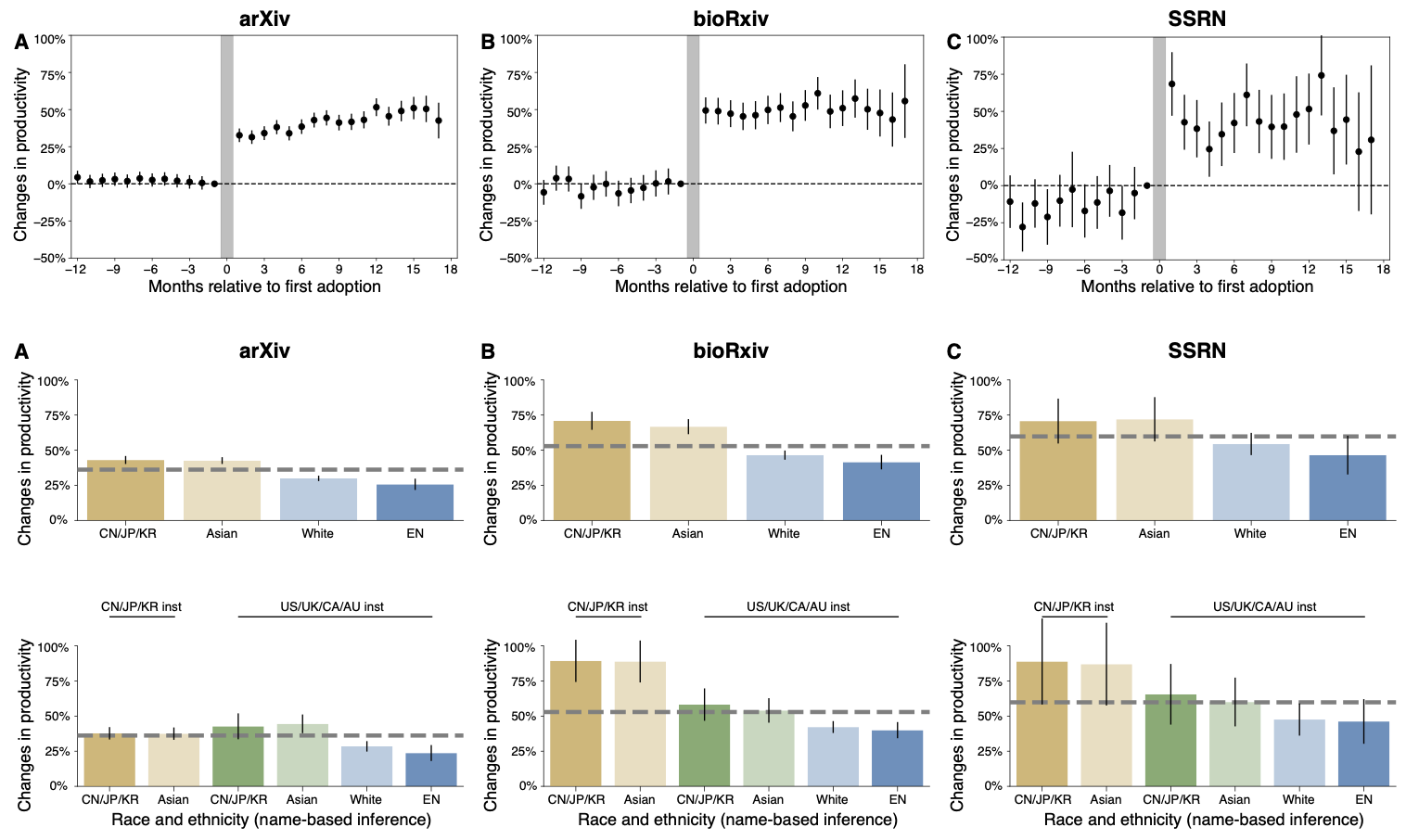
-
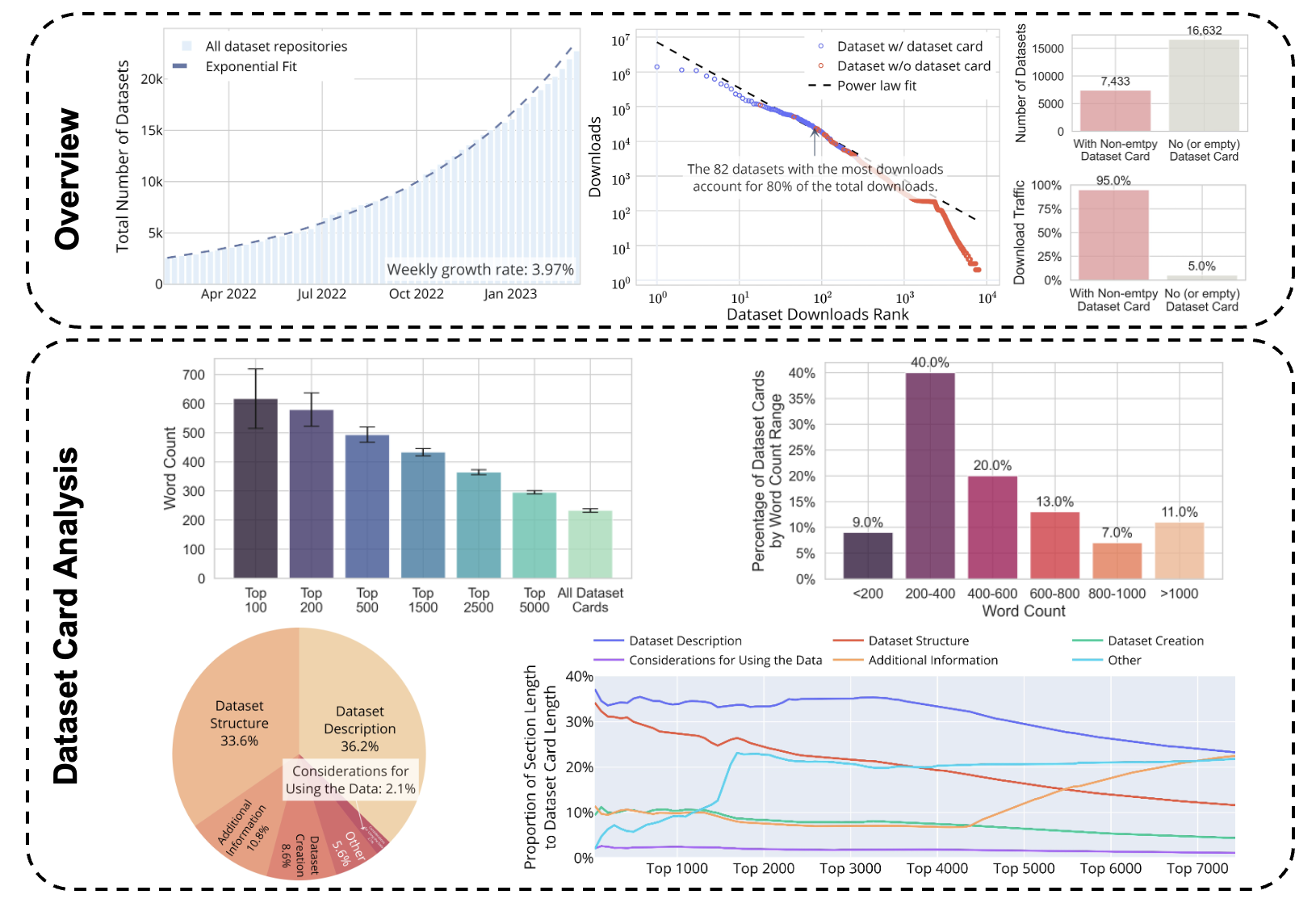
-
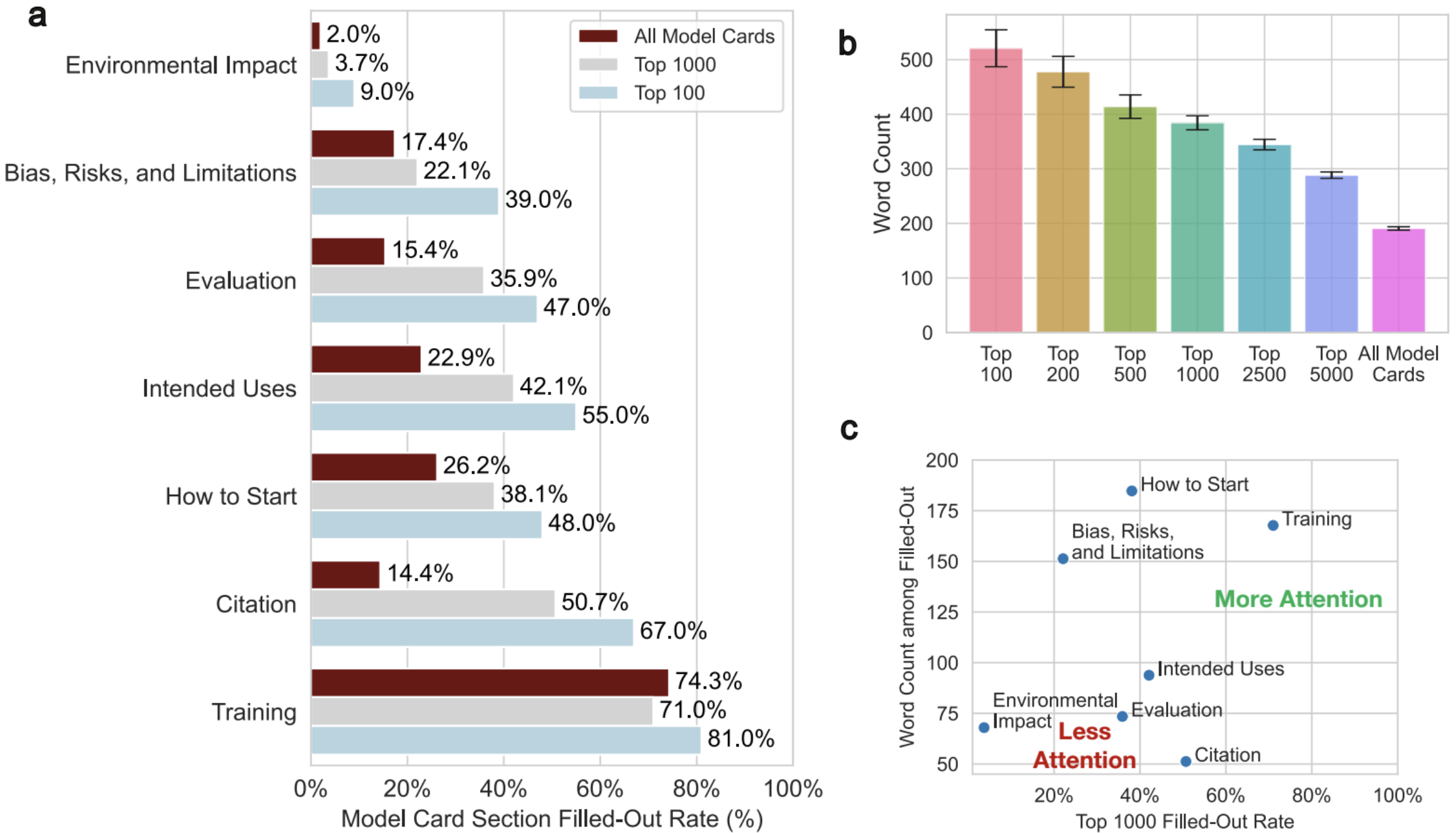
-

-
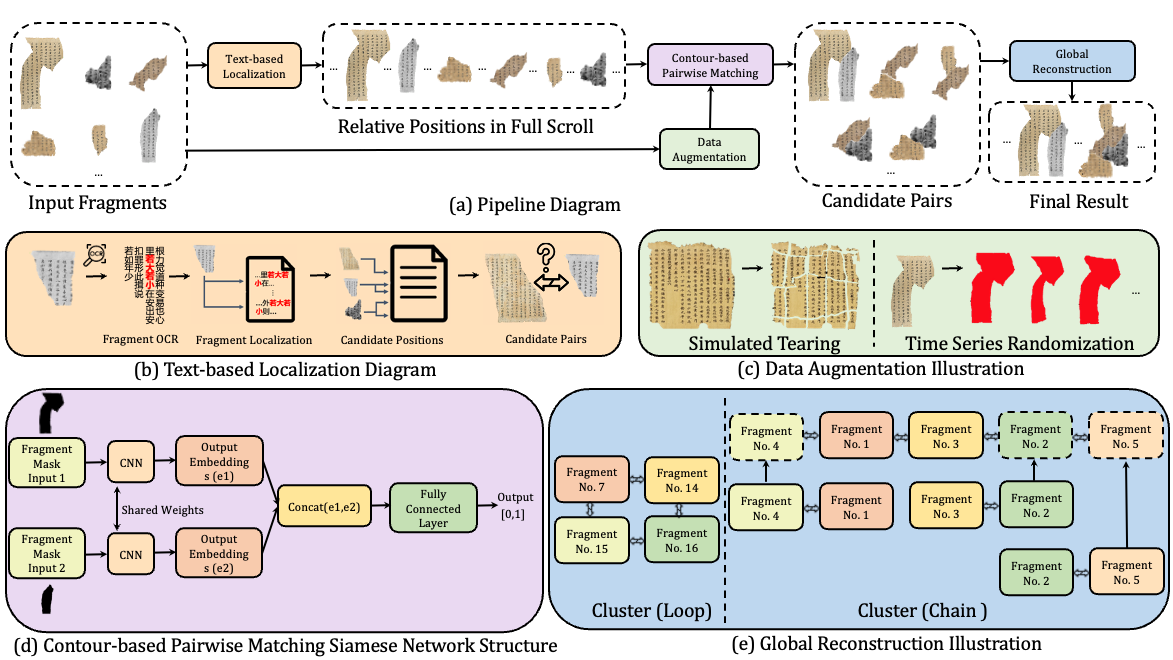 Reconnecting the Broken Civilization: Patchwork Integration of Fragments from Ancient ManuscriptsACM MM, 2023 (Oral)
Reconnecting the Broken Civilization: Patchwork Integration of Fragments from Ancient ManuscriptsACM MM, 2023 (Oral) -
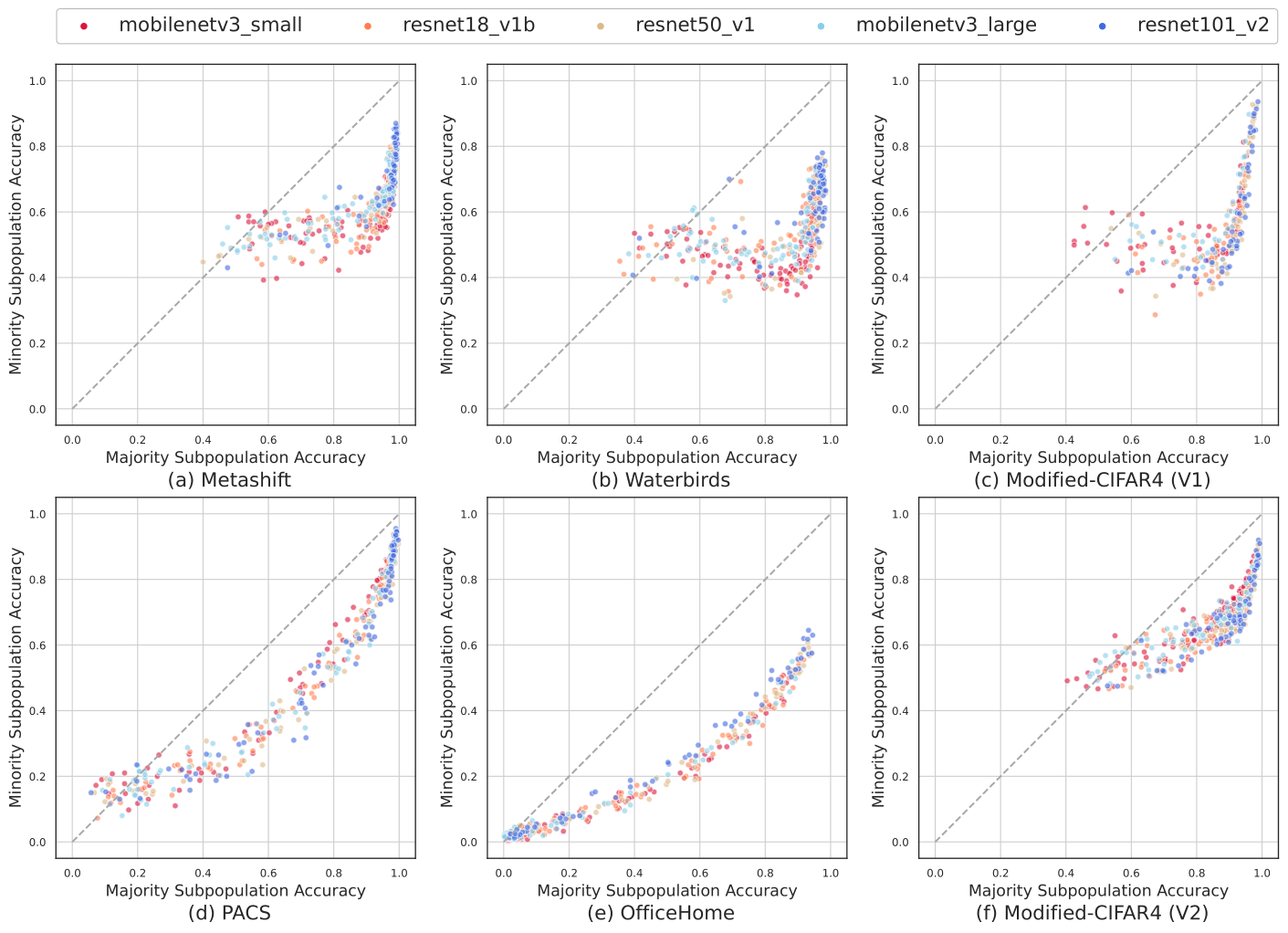
-
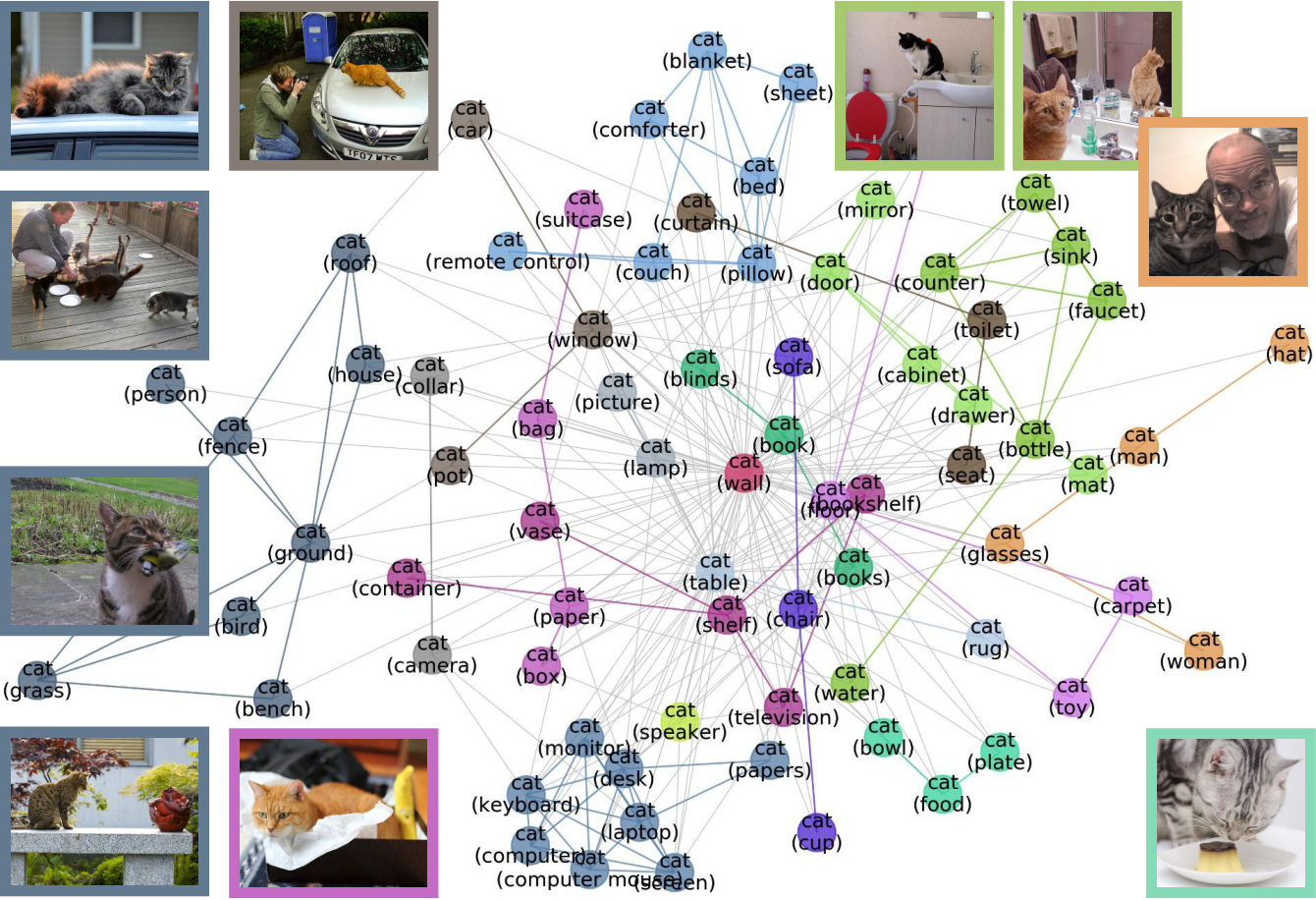
Awards & Honors
- 2022-2023Outstanding Graduates of Zhejiang Province
- 2022-2023Outstanding Graduates of Zhejiang University
- 2021-2022First-Class Scholarship for Outstanding Students, Zhejiang University
- 2020-2021Second-Class Scholarship for Outstanding Students, Zhejiang University
- 2019-2020National Scholarship
- 2019-2020First-Class Scholarship for Outstanding Students, Zhejiang University
- 2019-2020Outstanding Student Awards in Yunfeng College (15 out of 800 students)
Service
- ReviewerNeurIPS 2024-2025, NeurIPS D&B 2024, ICLR 2025, ICML 2025, CVPR 2026
- TeachingTeaching Assistant, Networks, Cornell University (Fall 2024)
- TeachingTeaching Assistant, Python Programming, Zhejiang University (Spring 2023)
Misc
- I started learning Chinese Calligraphy (a traditional form of writing characters from the Chinese language through the use of ink and a brush) and sketchy when I was nine. [Gallery]
- I love art and sports. I enjoy painting, photography, table tennis, piano, and classical music.